02: Interpreted vs Compiled Languages
UC Irvine - Fall ‘22 - ICS 45C

Quick list of things I want to talk about:
- Main differences
- How to compile?
- Compiler flags
- -std=c++11
- -Wall -Wextra -Wpedantic -Werror
Expanded notes:
C++ is a compiled language, which might be a new thing for you if your experience before was with an interpreted language like Python.
How are they different?
The main difference between the two workflows is that interpreted languages require a program (an interpreter) that translates source code to machine code on-the-fly. So when you try running your source code, the interpreter needs to go line-by-line telling the machine what to do.
A compiled language doesn’t need to do that. Instead, it uses a different program (a compiler) that translates your entire code all at once into an executable binary. Your machine knows how to execute this binary directly, so it doesn’t need a “translator” at runtime.
I think the following figure gives a nice visual explanation:
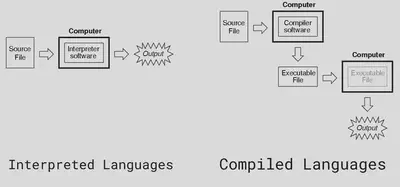
Interpreted Language
When you use an interpreted language, the first thing you need to install is an interpreter. For example, when you have some code like this:from math import pi
print(f"{pi=}")
You can run it with python3 source.py.
python3 is an interpreter, and it will go line-by-line figuring out what to do.
First, it’ll go find the math file, and inside that, find pi so we can copy it.
Once it’s done doing that, we’ll go to the following line, read it and execute it.
Compiled Language
When you’re using a compiled language, you need to install a compiler. The compiler is different than an interpreter because it won’t try to execute your code line-by-line. It will actually get all your files combined, figure out the sequence of statements you want to run, and then create a single file that has all instructions to do what you wanted.
So instead of reading one line and figuring out what we have to do, it will look at your entire code, look for any syntax/semantic errors, and create an executable that can be run.
Once you have that executable, the compiler isn’t needed anymore. The executable can be run directly on computers of the target platform.
Key differences
So from the descriptions above, the major difference in the workflow is that code for interpreted languages doesn’t “get read” until they’re about to executed by the interpreter. While compiled code is fully transformed into a single executable binary file, which doesn’t require an interpreter to be run.
This brings a few differences, for example:
- Deployment: if you make a program with a compiled language and want to share with others, you just need to compile your code for the correct platform and send the binary.
For example, if you’re using a Windows machine, you could compile it on your own machine, send just the binary to a different machine that has the same platform and it should run the same.
This lets you “hide” your code a little better, and also makes it easier for folks to run your programs as they can just double-click it.
If you’re using an interpreted language, usually, you’d send them the source file and tell them to install the interpreter. The alternative would be to package an interpreter into a file with your source code, but that would get much larger!
- Portability: continuing on the same example above, if you compile a code for a certain platform (e.g., Windows/Mac/Linux, Intel/AMD/ARM), it should run the same way on other machines with the same platform.
However, it is very much possible that your code runs differently on Windows than the way it runs on Mac. This is usually the source of those jokes that say “but it runs on my machine!”, because this actually happens. Executable binaries are created to run on that specific machine, so it might use platform-specific instructions, which could make it run better on a certain machine.
Interpreted languages, on the other hand, are more portable. Since you need to install an interpreter, you could share code between machines because each one would have an interpreter that can translate the source code to its specific instructions.
- Overhead: compiled languages usually have a much smaller overhead than interpreted ones when running. By overhead, you can think of how much memory it uses or how fast it finishes executing the same code. This happens because your binary file already knows exactly what it needs to do; it doesn’t need the interpreter to think line-by-line what’s going on.
A minimal C++ program
So if you want to create a minimal C++ program, you’d probably end up with something like this:
int main () {
// Other code goes here... (PS: anything in a line after "//" is a comment!)
return 0;
}
This program doesn’t do anything besides letting the computer know it didn’t crash.
So what’s all of this?
Since the C++ compiler combines all files together, it doesn’t know where it should start executing.
So you need to say what’s the starting point, and you do that by defining a main function.
The main function has a type of int, and doesn’t require arguments, so its signature is int main().
The code-block inside the function is defined by brackets ({})!
Proper indentation is nice to make the code readable, but it’s not required.
Then, at the very end, it returns 0, which lets the computer know the run was a success.
Notice the ; after return 0!
Every statement (assignment, function call, return) needs a semicolon after it.
We will cover functions more in-depth later in the quarter, so for now you’ll just need to define the main function like above and insert your code inside.
That is, you should have int main(), then brackets to define what code should be executed, and return 0; right before the closing bracket.
Compiling a C++ program
Once you have your source file(s) saved somewhere, you can open a terminal and navigate to that directory:
cd /my/folder
And then compile it:
g++ my_file.cpp
Keep in mind that if you’re on Mac and using clang, you might need to replace g++ with clang++!
If compilation succeeds, you should se a file named a.out or (a.exe on Windows) in the same directory.
Note that we’re using the terminal to compile and run code. We’ll use VS Code as a text editor with highlight syntax, some autocomplete, and autoformatting. Although it might be overkill, the main reason we’re using it is for the autoformatting! Please get comfortable compiling/running things in the terminal, as this will come in handy in future classes.
Flags
Compilers in different platforms and versions might produce different executables, have different syntax they accept, try to fix common mistakes differently, and so on.
Because of that, we use a few compilation flags to make sure all our executables are as similar as possible.
- -std=c++11
- -Wall
- -Wextra
- -Wpedantic
- -Werror
- -o
C++ has many versions, and some of them eventually become ISO standards. For this class, we will use the C++11 standard. By using this flag, you’re telling the compiler which version of C++ you intended to use, so it should complain about newer syntax.
All these flags turn on extra warnings.
Warnings are important so they indicate what changes you should make.
For example, even if you use -std=c++11, the compiler might still accept instructions from newer versions.
So you need to turn on extra diagnostics (warnings) to get messages that might be relevant to you.
Even if you get a warning, the compiler still outputs an executable for you. This flag tells the compiler that you don’t want that to happen; if there is a warning, you want it to be treated like an error. By using this flag, you ensure that once you have an executable, there were no warnings in your code.
By default, the compiler will create an executable named a.out.
That’s not very descriptive though.
Maybe you named your file hello.cpp, so it would probably make sense to name your executable hello.
That way, if you have many source files in the same directory, it should be easier to track what’s each executable.
By convention, given a source.cpp file, we usually name our executable source in Linux/Mac, or source.exe on Windows.
Final command
Now that we want to use these flags, we just add them to the end of the previous command:
g++ my_file.cpp -std=c++11 -Wall -Wextra -Wpedantic -Werror -o my_file
This should generate an executable my_file.
Running the executable
If your compilation succeeded, you should have an executable file with the name you defined.
Once you have the executable, you can open a terminal, navigate to the directory with your file, and run it with ./my_file (or .\my_file.exe on Windows).
We’re telling the terminal to look for our file in the current directory (i.e., ./ or .\), and then the name of the file.
Since this is an executable file, it should just run it.
Note that once you have a binary, you can run it as many times as you want. However, changes on the source do not reflect immediately on the binary. So you only need to compile your source file again if you have made changes.
If you compiled the “minimal program”, then you shouldn’t see anything in the screen though! We’ll see how to input/output things on the next set of notes, so your programs should start doing more things.
References
- Comic reference: https://xkcd.com/303/
- Figure 1 reference: https://www.learningelectronics.net/vol_5/chpt_7/3.html